Ahana Cloud for Presto review: Fast SQL queries against data lakes
Ahana Cloud for Presto turns a data lake on Amazon S3 into what is effectively a data warehouse, without moving any data. SQL queries run quickly even when joining multiple heterogeneous data sources.






Contributing Editor, InfoWorld |

-
Ahana Cloud for Presto
Hope springs eternal in the database business. While we’re still hearing about data warehouses (fast analysis databases, typically featuring in-memory columnar storage) and tools that improve the ETL step (extract, transform, and load), we’re also hearing about improvements in data lakes (which store data in its native format) and data federation (on-demand data integration of heterogeneous data stores).
Presto keeps coming up as a fast way to perform SQL queries on big data that resides in data lake files. Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes. Presto allows querying data where it lives, including Hive, Cassandra, relational databases, and proprietary data stores. A single Presto query can combine data from multiple sources. Facebook uses Presto for interactive queries against several internal data stores, including their 300PB data warehouse.
The Presto Foundation is the organization that oversees the development of the Presto open source project. Facebook, Uber, Twitter, and Alibaba founded the Presto Foundation. Additional members now include Alluxio, Ahana, Upsolver, and Intel.
Ahana Cloud for Presto, the subject of this review, is a managed service that simplifies Presto for the cloud. As we’ll see, Ahana Cloud for Presto runs on Amazon, has a fairly simple user interface, and has end-to-end cluster lifecycle management. It runs in Kubernetes and is highly scalable. It has a built-in catalog and easy integration with data sources, catalogs, and dashboarding tools.
Competitors to Ahana Cloud for Presto include Databricks Delta Lake, Qubole, and BlazingSQL. I will draw comparisons at the end of the article.
Presto and Ahana architecture
Presto is not a general-purpose relational database. Rather, it is a tool designed to efficiently query vast amounts of data using distributed SQL queries. While it can replace tools that query HDFS using pipelines of MapReduce jobs such as Hive or Pig, Presto has been extended to operate over different kinds of data sources including traditional relational databases and other data sources such as Cassandra.
In short, Presto is not designed for online transaction processing (OLTP), but for online analytical processing (OLAP) including data analysis, aggregating large amounts of data, and producing reports. It can query a wide variety of data sources, from files to databases, and return results to a number of BI and analysis environments.
Presto is an open source project that operated under the auspices of Facebook. It was invented at Facebook and the project continues to be developed by both Facebook internal developers and a number of third-party developers under the supervision of the Presto Foundation.
Presto’s scalable, clustered architecture uses a coordinator for SQL parsing, planning, and scheduling, and a number of worker nodes for query execution. Result sets from the workers flow back to the client through the coordinator.
Ahana Cloud packages managed Presto, a Hive metadata catalog, a data lake hosted on Amazon S3, cluster management, and access to Amazon databases into what is effectively a cloud data warehouse in an open, disaggregated stack, as shown in the architecture diagram below. The Presto Hive connector manages access to ORC, Parquet, CSV, and other data files.
 Ahana
Ahana
The Ahana control plane takes care of cluster orchestration, logging, security and access control, billing, and support. The Presto clusters and the storage live inside the customer’s VPC.
Using Ahana Cloud for Presto
Ahana provided me with a hands-on lab that allowed me to create a cluster, connect it to sources in Amazon S3 and Amazon RDS MySQL, and exercise Presto using SQL from Apache Superset. Superset is a modern data exploration and visualization platform. I didn’t really exercise the visualization portion of Superset, as the point of the exercise was to look at SQL performance using Presto.
 IDG
IDG
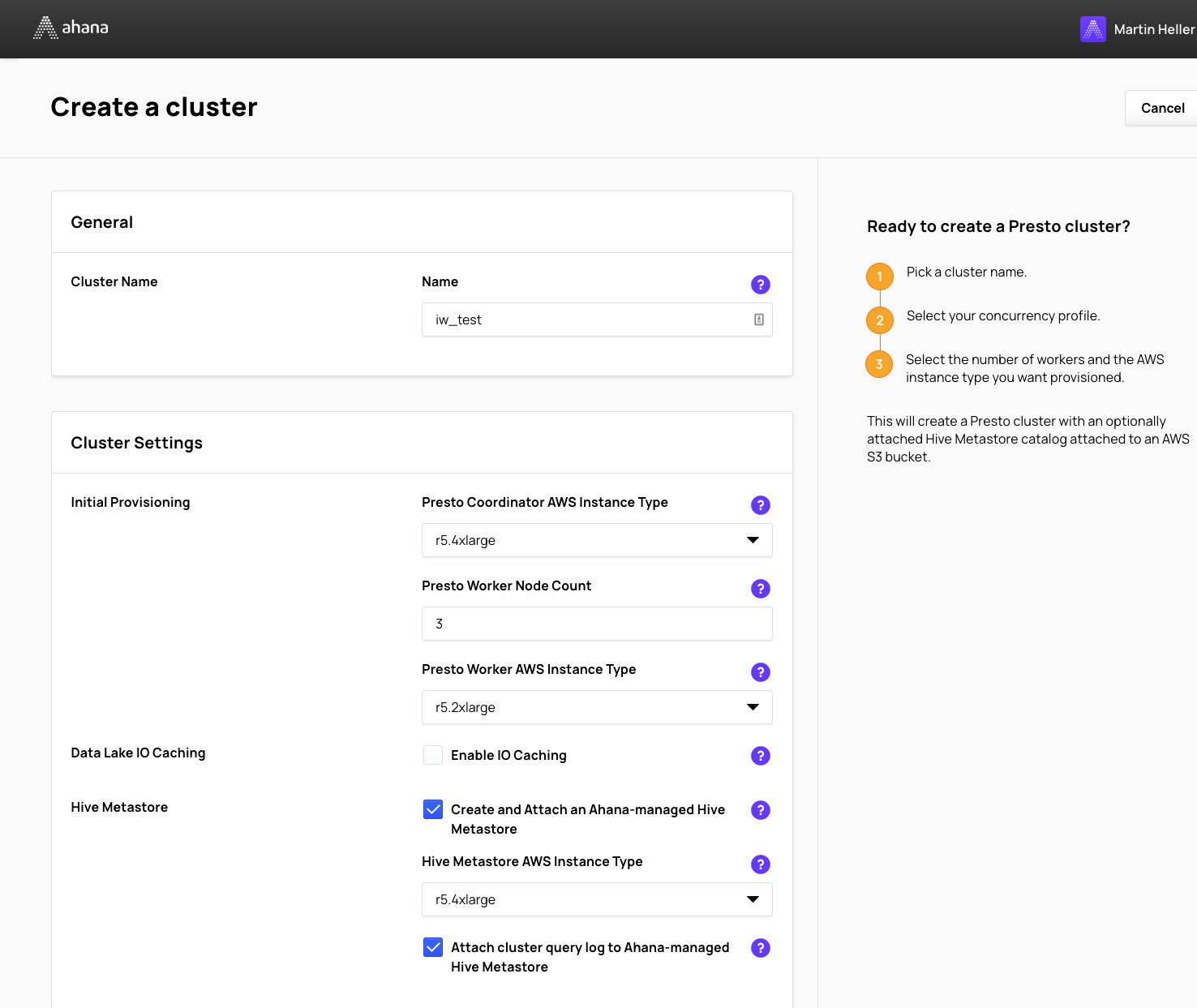
When you create a Presto cluster in Ahana, you choose your instance types for the coordinator, metastore, and workers, and the initial number of workers. You can scale the number of workers up or down later. Because the datasets I was using were relatively small (only millions of rows), I didn’t bother enabling I/O caching, which is a new feature of Ahana Cloud.
 IDG
IDG
The Clusters pane of the Ahana interface shows your active, pending, and inactive clusters. The PrestoDB Console shows the status of the running cluster.
I found the process of adding data sources a bit annoying because it required me to edit URI strings and JSON configuration strings. It would have been easier if the strings had been assembled from pieces in separate text boxes, especially if the text boxes were populated automatically.
 IDG
IDG
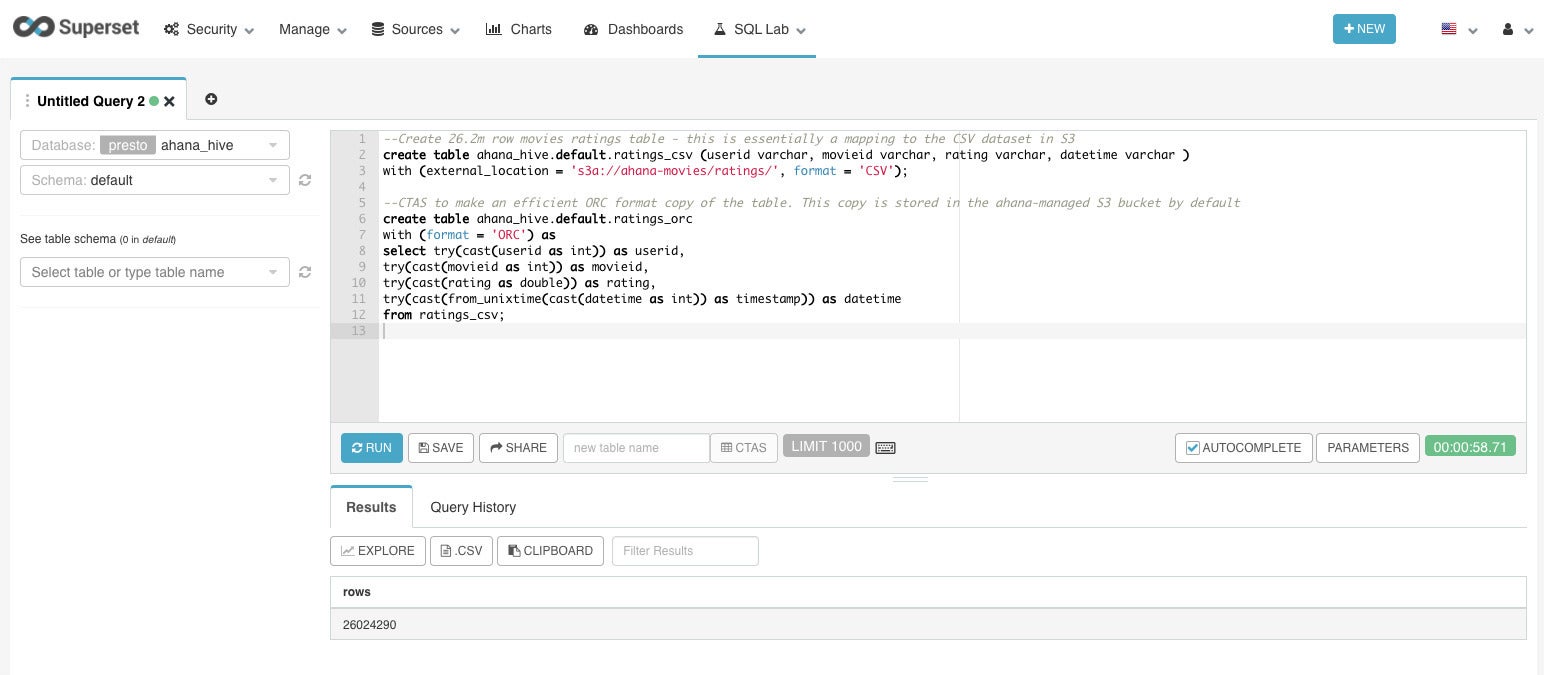
Creating catalogs and converting from CSV to ORC format took just under a minute, for 26.2 million rows of movie ratings. Querying an ORC file is much faster than querying a CSV file. For example, counting the ORC file takes 2.5 seconds, while counting the CSV file takes 48.6 seconds.
 IDG
IDG
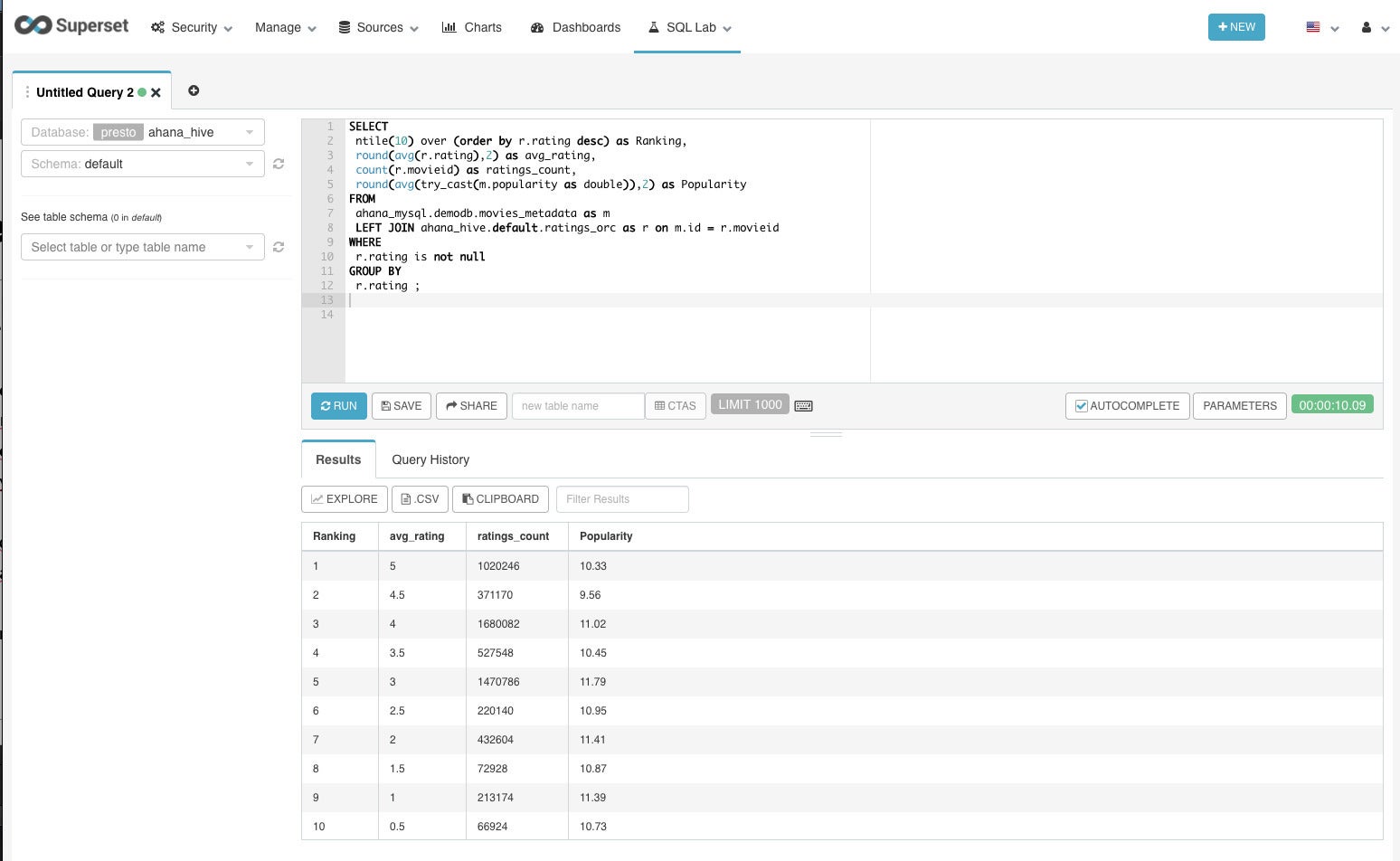
This federated query joins movie ratings in ORC format with movie data in a MySQL database table to create a list of ratings, counts, and popularity broken down into deciles. It took 10 seconds.
 IDG
IDG
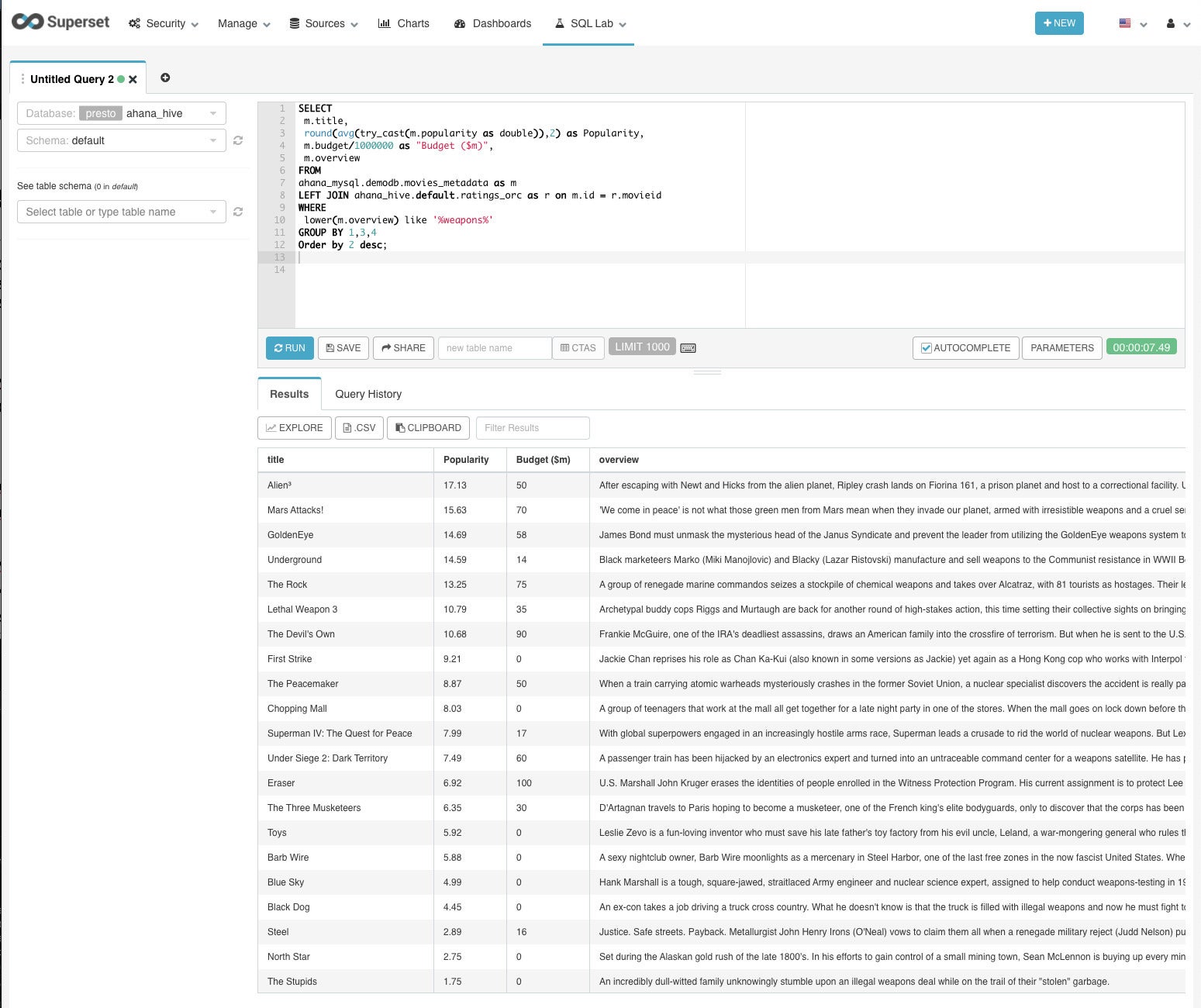
This query computes the most popular movies in the federated database with a description that mentions weapons, and also reports the movies’ budgets. The query took 7.5 seconds.
How to integrate Ahana Presto with machine learning and deep learning
How do people integrate Ahana Presto with machine learning and deep learning? Typically, rather than using Superset as a client, they use a notebook, either Jupyter or Zeppelin. To perform the SQL query, they use a JDBC link to the Ahana Presto query engine. Then the output from the SQL query populates the appropriate structure or data frame for use in machine learning, depending on the framework used.
New features of Ahana Cloud for Presto
The version of Ahana Cloud I tested incorporated the improvements announced on March 24, 2021. These included performance improvements such as data lake I/O caching and tuned query optimization, and ease of use improvements such as automated and versioned upgrades of Ahana Compute Plane.
I didn’t use all of them myself. For example, I didn’t enable data lake I/O caching because the data lake table I was using was too small, and I didn’t spend long enough with Ahana to see a version upgrade.
Ahana Cloud for Presto vs. competitors
Overall, Ahana Cloud for Presto is a good way to turn a data lake on Amazon S3 into what is effectively a data warehouse, without moving any data. Using Ahana Cloud avoids most of the work required to set up and tune Presto and Apache Superset. SQL queries run quickly on Ahana Cloud for Presto, even when they are joining multiple heterogeneous data sources.
Databricks Delta Lake uses different technologies to accomplish some of the same things as Ahana Cloud for Presto. All the files in Databricks Delta Lake are in Apache Parquet format, and Delta Lake uses Apache Spark for SQL queries. Like Ahana Cloud for Presto, Databricks Delta Lake can speed up SQL queries with an integrated cache. Delta Lake can’t perform federated queries, however.
Qubole, a cloud-native data platform for analytics and machine learning, helps you to ingest datasets from a data lake, build schemas with Hive, query the data with Hive, Presto, Quantum, and/or Spark, and continue to your data engineering and data science. You can use Zeppelin or Jupyter notebooks, and Airflow workflows. In addition, Qubole helps you manage your cloud spending in a platform-independent way. Unlike Ahana, Qubole can run on AWS, Microsoft Azure, Google Cloud Platform, and Oracle Cloud.
BlazingSQL is an even faster way of running SQL queries, using Nvidia GPUs and running SQL on data loaded into GPU memory. BlazingSQL lets you ETL raw data directly into GPU memory as GPU DataFrames. Once you have GPU DataFrames in GPU memory, you can use RAPIDS cuML for machine learning, or convert the DataFrames to DLPack or NVTabular for in-GPU deep learning with PyTorch or TensorFlow.
Ahana Cloud for Presto is a worthwhile alternative to its competitors, and is easier to set up and maintain than an open source Presto deployment. It’s certainly worth the effort of a free trial.
—
Cost: $0.25/Ahana Cloud Credit (ACC) hour. See pricing calculator and table of instance charges. Example: Presto Cluster of 10 x r5.xlarge running every workday costs $256/month.
Platform: Runs on Amazon Elastic Kubernetes Service.
Copyright © 2021 IDG Communications, Inc.