Review: Databricks Lakehouse Platform
Databricks Lakehouse Platform combines cost-effective data storage with machine learning and data analytics, and it's available on AWS, Azure, and GCP. Could it be an affordable alternative for your data warehouse needs?






Contributing Editor, InfoWorld |

-
Databricks Lakehouse Platform
- Getting started with Databricks Lakehouse
- Delta Lake
- Data science and engineering on Databricks Lakehouse
- Machine learning on Databricks Lakehouse
- SQL queries on Databricks Lakehouse
- Unity Catalog and Delta Sharing
Data lakes and data warehouses used to be completely different animals, but now they seem to be merging. A data lake was a single data repository that held all your data for analysis. The data was stored in its native form, at least initially. A data warehouse was an analytic database, usually relational, created from two or more data sources. The data warehouse was typically used to store historical data, most often using a star schema or at least a large set of indexes to support queries.
Data lakes contained a very large amount of data and usually resided on Apache Hadoop clusters of commodity computers, using HDFS (Hadoop Distributed File System) and open source analytics frameworks. Originally, analytics meant MapReduce, but Apache Spark made a huge improvement in processing speed. It also supported stream processing and machine learning, as well as analyzing historic data. Data lakes didn’t impose a schema on data until it was used—a process known as schema on read.
Data warehouses tended to have less data but it was better curated, with a predetermined schema that was imposed as the data was written (schema on write). Since they were designed primarily for fast analysis, data warehouses used the fastest possible storage, including solid-state disks (SSDs) once they were available, and as much RAM as possible. That made the storage hardware for data warehouses expensive.
Databricks was founded by the people behind Apache Spark, and the company still contributes heavily to the open source Spark project. Databricks has also contributed several other products to open source, including MLflow, Delta Lake, Delta Sharing, Redash, and Koalas.
This review is about Databricks’ current commercial cloud offering, Databricks Lakehouse Platform. Lakehouse, as you might guess, is a portmanteau of data lake and data warehouse. The platform essentially adds fast SQL, a data catalog, and analytics capabilities to a data lake. It has the functionality of a data warehouse without the need for expensive storage.
Direct competitors to Databricks Lakehouse Platform include Dremio, Ahana Presto, and Amazon Athena, in addition to the open source project, Apache Spark. Data warehouses that support external tables, such as Snowflake and Azure Synapse Analytics are indirect competitors.
The following screenshot is an overview of Databricks Lakehouse Platform. Note that as of this writing, Unity Catalog is not yet generally available.
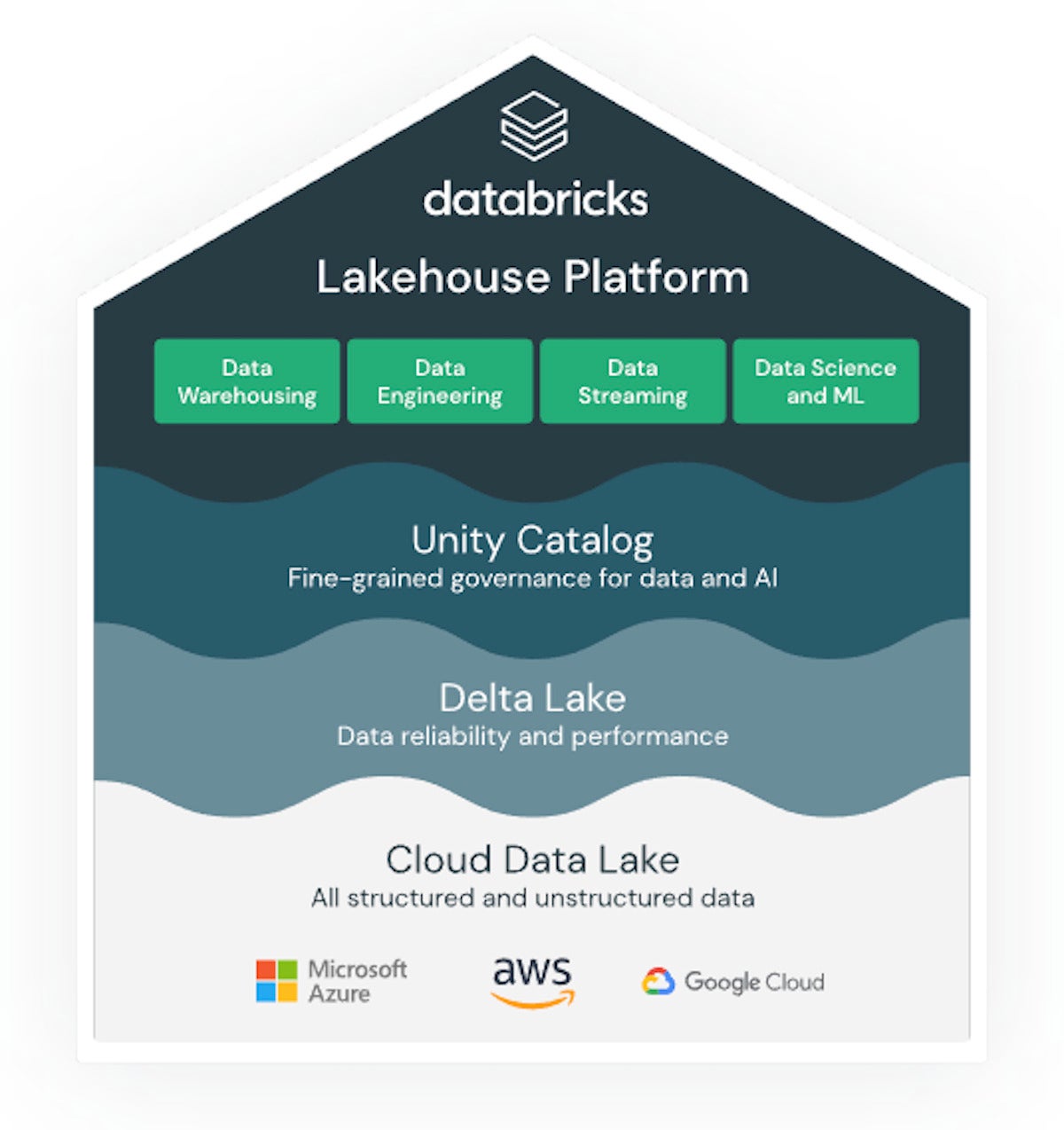 IDG
IDG
A top-level view of Databricks Lakehouse Platform.
Getting started with Databricks Lakehouse
Databricks Lakehouse Platform is offered on the three major clouds: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). It is also available on Alibaba. Databricks Lakehouse is supported as a first-party product on Azure, which is where I did my hands-on trial for this review. The platform is not offered on-prem, although you can deploy its open source products wherever you wish.
While you can accomplish most data science, data engineering, and machine learning tasks in Databricks Lakehouse using notebooks, the command-line interface, and the console interface, you can also use various client tools and languages. Databricks notebooks support Python, R, and Scala.
Databricks Lakehouse supports Eclipse, IntelliJ, Jupyter, PyCharm, SBT, sparklyr and RStudio Desktop, SparkR and RStudio Desktop, and Visual Studio Code for external IDEs. It also has connectors and drivers, including the Databricks SQL Connector for Python, pyodbc, the Databricks ODBC driver, and the Databricks JDBC driverCloud interfaces.
Here's a look at the opening screen for Azure Databricks.
 IDG
IDG
The Get Started column on the left offers introductory actions; the Data Science & Engineering screen on the right points to routine actions.
I went through three tutorials using Azure Databricks. One covered basic data science and engineering using the lakehouse architecture provided by Delta Lake. The other two covered machine learning and SQL, respectively.
Delta Lake
The Delta Lake documentation describes Delta Lake as an open source project that can be used to build a lakehouse architecture on top of existing data lakes such as Amazon S3, Azure Data Lake Storage, Google Cloud Storage, and HDFS. Delta Lake provides ACID transactions, scalable metadata handling, and it unifies streaming and batch data processing.
The Delta Lake documentation has more about these offerings:
- ACID transactions on Spark: Serializable isolation levels ensure that readers never see inconsistent data.
- Scalable metadata handling: Leverages Spark distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease.
- Streaming and batch unification: A table in Delta Lake is a batch table as well as a streaming source and sink. Streaming data ingest, batch historic backfill, interactive queries all just work out of the box.
- Schema enforcement: Automatically handles schema variations to prevent insertion of bad records during ingestion.
- Time travel: Data versioning enables rollbacks, full historical audit trails, and reproducible machine learning experiments.
- Upserts and deletes: Supports merge, update and delete operations to enable complex use cases like change-data-capture, slowly-changing-dimension (SCD) operations, streaming upserts, and so on.
The Delta file format combines the information needed to support Delta Lake operations with a Parquet file, meaning that it carries over Parquet’s efficient compressed columnar storage. The additional transaction log is written in JSON format in a subdirectory.
Data science and engineering on Databricks Lakehouse
It took me about two hours to step through the data science and engineering notebook supplied for this trial.
The Delta format is an enhancement of the Parquet format, so you can substitute the word “delta” for the word “parquet” in Apache Spark and Spark SQL commands.
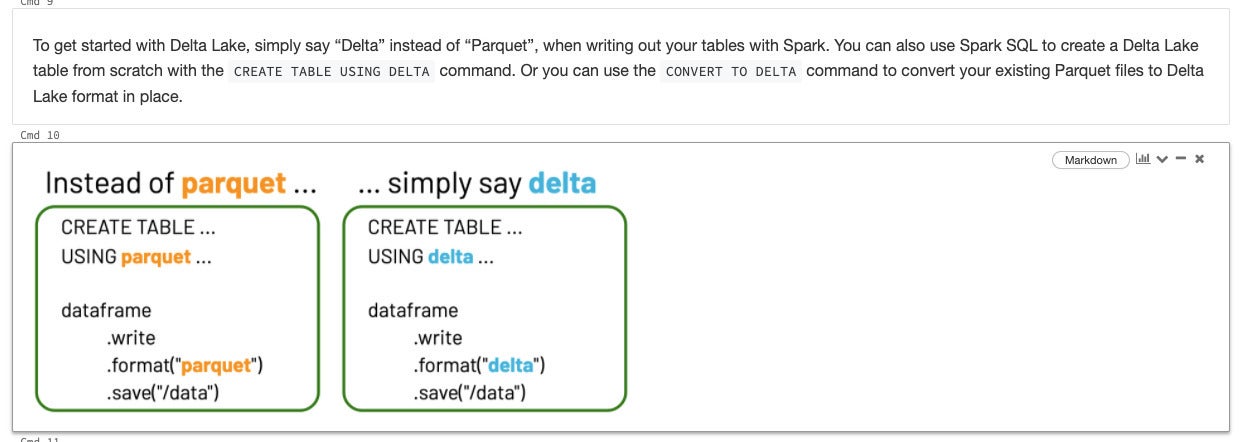 IDG
IDG
The Delta format is an enhancement of the Parquet format.
Before you can do much with a Databricks notebook or workspace, you need to create or access a compute cluster and attach it to the notebook you want to execute. In the following screenshot, we see the configuration of a standard cluster for running notebooks.
 IDG
IDG
A standard cluster configured for running notebooks.
There are three basic ways to upgrade a Parquet table to a Delta table. In a Spark Python notebook, you can use spark.read.format("parquet") to read a Parquet file into a data frame and then write it out using the data frame’s write.format("delta") method.
 IDG
IDG
Upgrading a Parquet table to a Delta table in a Spark Python notebook.
You can accomplish essentially the same thing using the Spark SQL construction CREATE TABLE USING delta AS SELECT * FROM parquet.''