Review: Redpanda gives Kafka a run for its money
The Kafka-compatible distributed event streaming platform excels in latency and performance and offers a glimpse into the future of streaming with inline WebAssembly transforms and more.







-
Redpanda
- Redpanda vs. Kafka
- Redpanda's architecture and optimizations
- Installing and testing Redpanda
- Redpanda production deployment options
- Redpanda Jepsen testing
- Conclusion
Apache Kafka is an open-source Java/Scala distributed event streaming platform for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. As I have explained, one downside of Kafka is that setting up large Kafka clusters can be tricky. Another downside is that Kafka uses the Java virtual machine (JVM), which introduces lag because of memory garbage collection. Adding even more complexity, Kafka has until recently required Apache ZooKeeper for distributed coordination, and it requires a separate schema registry process.
Redpanda (previously called Vectorized) is a Kafka plug-in replacement written primarily in C++ using the Seastar asynchronous framework, and the Raft consensus algorithm for its distributed log. Redpanda does not require using ZooKeeper or the JVM, and its source is available on GitHub under the Business Source License (BSL). It's not technically open source as defined by the Open Software Foundation, but that doesn't matter to me because I have no plans to offer Redpanda as a service.
Redpanda vs. Kafka
As you might expect from the reimplementation in C++, Redpanda has significantly lower latency and higher performance than Kafka. It's also much easier to install and tune.
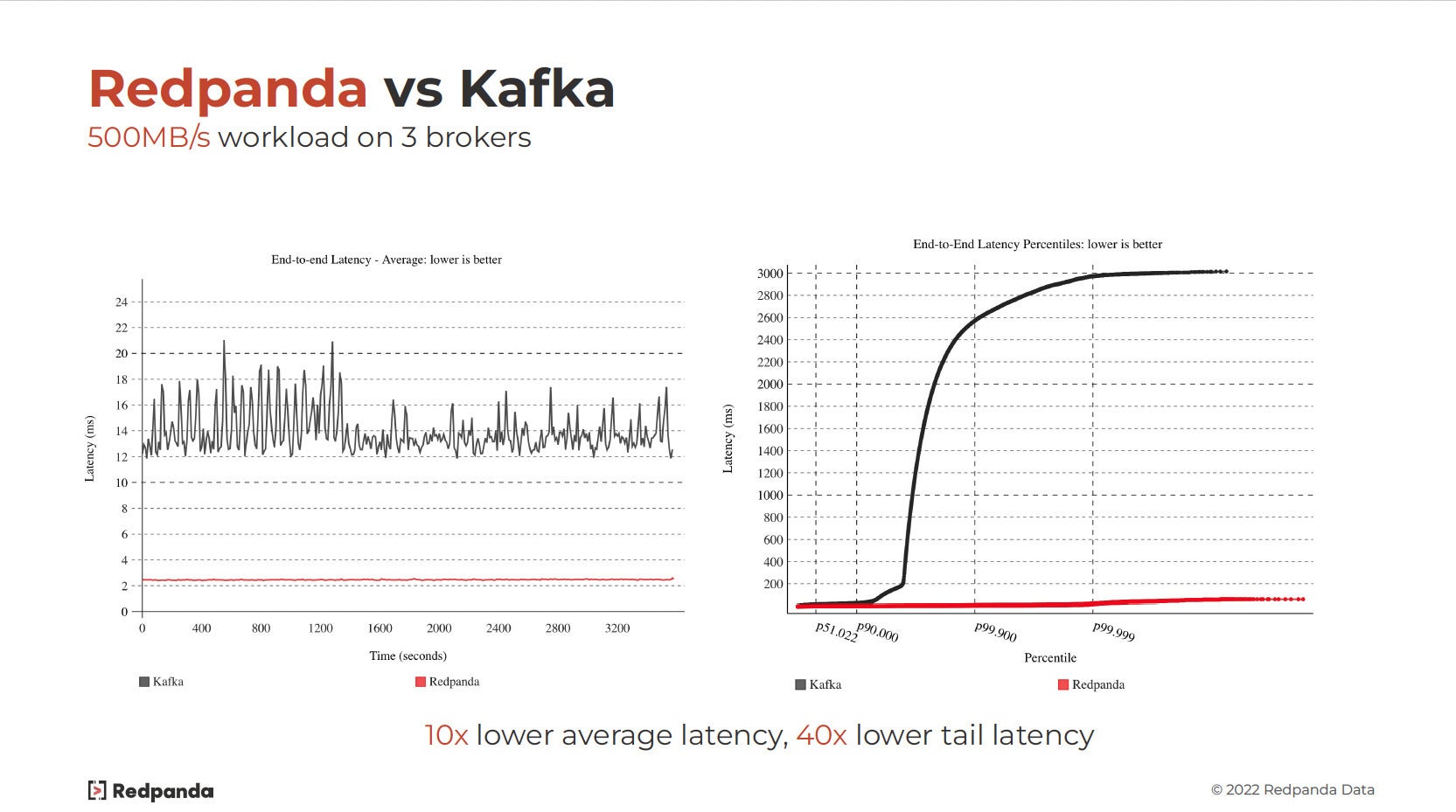
Figure 1 shows latency charts for Redpanda and Kafka. The left-hand chart shows average latency versus time, and the right-hand chart shows latency versus percentile. Redpanda's caption isn't exactly false, but it does exaggerate. I'd rephrase it and say that Kafka's average latency is 6 to 10 times higher than Redpanda's, and that Kafka's tail latency is up to 40 times higher than Redpanda's.
 IDG
IDG
Figure 1. Latency charts for Redpanda and Kafka.
Redpanda's architecture and optimizations
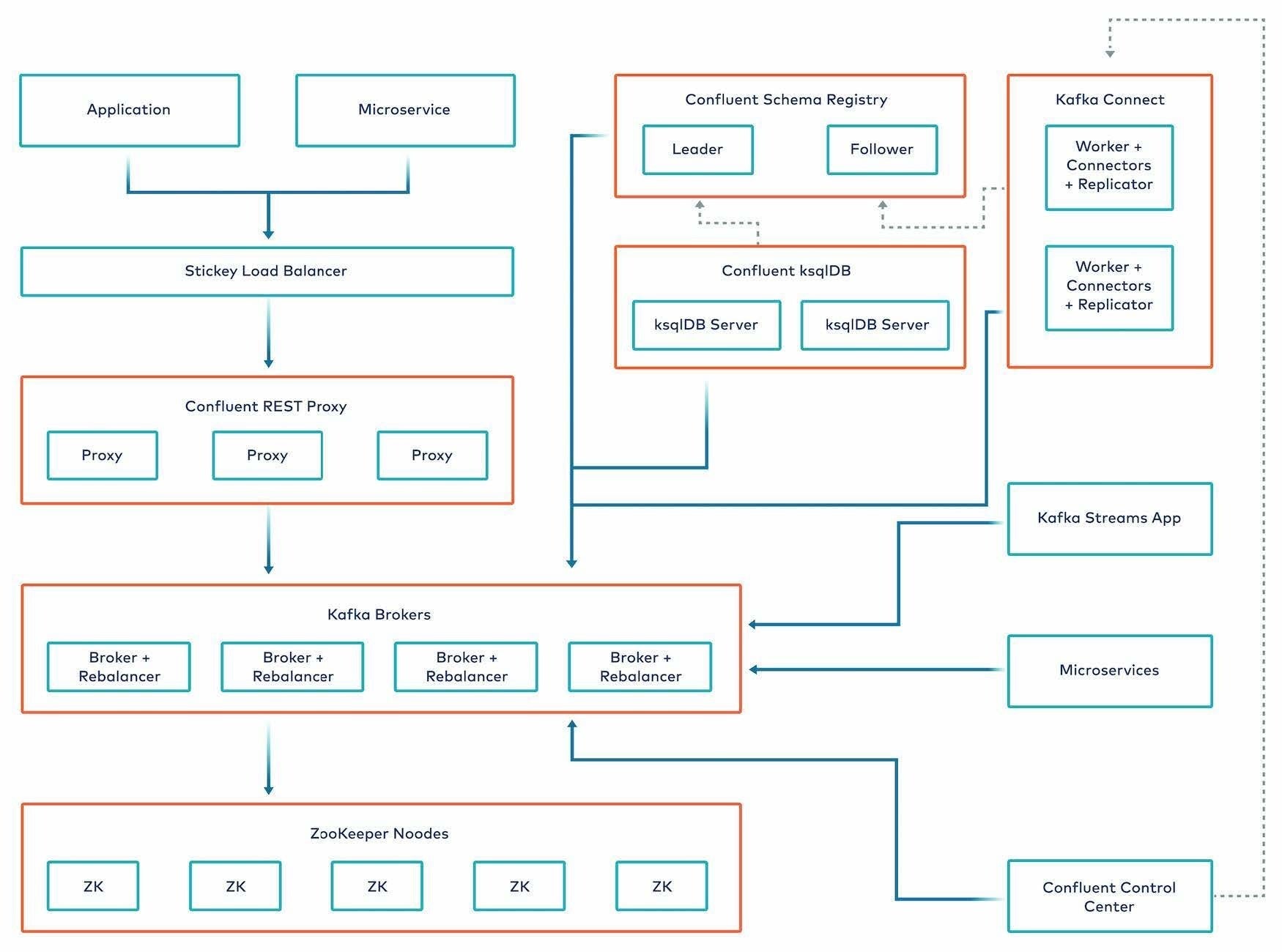
Kafka has a complicated architecture that is designed to scale, as shown in Figure 2 below. Redpanda has a simpler architecture, shown in Figure 3, but still outperforms Kafka by a large factor, especially when it comes to latency.
Redpanda boasts a number of optimizations over Kafka, starting with jettisoning the JVM and ZooKeeper, and continuing from there. Even beyond its reimplementation in C++, Redpanda uses an asynchronous, shared-nothing, thread-per-core model, with no locking, minimal context switching, and thread-local memory access. It scales well, both vertically (bigger, faster nodes) and horizontally (more nodes).
The Raft consensus algorithm speeds writes to a cluster, and Redpanda does automatic leader and partition balancing. In production mode, Redpanda auto-tunes. Simple one-shot tuning and configuration sets kernel parameters, and auto-detects and optimizes for available hardware.
Kafka relies on the Linux page cache to accelerate disk I/O, which has issues such as flushing the cache after a backup. Redpanda bypasses the Linux page cache to avoid its design flaws; instead, it uses custom memory management and I/O scheduling.
Redpanda goes beyond the Kafka protocol into the future of streaming with inline WebAssembly transforms and geo-replicated hierarchical storage/shadow indexing. WebAssembly (WASM) is a high-performance, system-independent byte code system that is compiled from other languages. Alexander Gallego, the founder and CEO of Redpanda, has said that "What JavaScript did for the web in the late '90s is what WebAssembly can do for server-side applications." Redpanda uses WASM to perform data transformations on streams without needing to use an external processor such as Apache Flink.
According to Redpanda, Shadow Indexing is a multi-tiered remote storage solution that provides the ability to archive log segments to a cloud object store in real time as the topic is being produced. You can recover a topic that no longer exists in the cluster, and replay and read log data as a stream directly from cloud storage even if it doesn’t exist in the cluster. Shadow Indexing provides a disaster recovery plan that takes advantage of infinitely scalable storage systems, is easy to configure, and works in real time.
Redpanda supports observability via Prometheus and Grafana. It has a metrics endpoint, and the rpm generate command can create configuration for both Prometheus and Grafana.
Architectural overview
As shown in Figure 2, Kafka's architecture is designed to scale. Each component is given its own servers, and if any layer becomes overloaded, you can scale it independently by adding nodes to that specific layer. For example, when adding applications that use the Confluent REST proxy, you may find that the REST proxy no longer provides the required throughput, while the underlying Kafka brokers still have spare capacity. In this case, you can scale your entire platform simply by adding REST proxy nodes.
 IDG
IDG
Figure 2. Confluent Kafka large-cluster architecture diagram.
The diagram in Figure 3 shows a three-node Redpanda cluster, where each cluster supports the Kafka API, an HTTP proxy, the Kafka schema registry, and a WebAssembly engine.
 IDG
IDG
Figure 3. High-level architecture of Redpanda.
Installing and testing Redpanda
You can install Redpanda on Linux and on Docker or Kubernetes containers running on macOS or Windows. You can also run Redpanda in either your own cloud or Redpanda's fully managed cloud. My first instinct, based on the difficulty of installing and managing Kafka clusters, was to use the Redpanda cloud. I was convinced to try installing Redpanda in Docker on one of my Macs; it turned out to be painless once I repaired and updated my old Homebrew installation.
Installation on macOS
As you can see from the log below, this installation wasn't a big deal: Homebrew installed RPK, which controls Redpanda and Docker. You can ignore Homebrew's complaints about my older macOS version: this is not a formula that struggles with macOS High Sierra. (That's the latest version that this iMac can run. Thanks, Apple.)
Martins-iMac:~ mheller$ brew install redpanda-data/tap/redpanda
==> Tapping redpanda-data/tap
Cloning into '/usr/local/Homebrew/Library/Taps/redpanda-data/homebrew-tap'...
remote: Enumerating objects: 333, done.
remote: Counting objects: 100% (4/4), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 333 (delta 0), reused 0 (delta 0), pack-reused 329
Receiving objects: 100% (333/333), 37.32 KiB | 1.96 MiB/s, done.
Resolving deltas: 100% (160/160), done.
Tapped 1 formula (15 files, 63.9KB).
Warning: You are using macOS 10.13.
We (and Apple) do not provide support for this old version.
You will encounter build failures with some formulae.
Please create pull requests instead of asking for help on Homebrew's GitHub,
Twitter or any other official channels. You are responsible for resolving
any issues you experience while you are running this
old version.
==> Downloading https://github.com/vectorizedio/redpanda/releases/download/v21.11.15/rpk-darwin-amd64.zip
==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-2e65be/309512982/e3c3b4bf-aa78-4e8c-a906-17299a824b06?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53
######################################################################## 100.0%
==> Installing redpanda from redpanda-data/tap
==> Caveats
Redpanda - The fastest queue in the west!
This installs RPK which, with Docker, enables the running of a local cluster
for testing purposes.
You can start a 3 node cluster locally using the following command:
rpk container start -n 3
You can then interact with the cluster using commands like the following:
rpk topic list
When done, you can stop and delete the cluster with the following command:
rpk container purge
For information on how to setup production evironments, check out our
installation guide here: https://vectorized.io/documentation/setup-guide/
==> Summary
🍺 /usr/local/Cellar/redpanda/21.11.15: 3 files, 23.6MB, built in 5 seconds
==> Running `brew cleanup redpanda`...
Disable this behaviour by setting HOMEBREW_NO_INSTALL_CLEANUP.
Hide these hints with HOMEBREW_NO_ENV_HINTS (see `man brew`).