The best open source software of 2019
InfoWorld recognizes the leading open source projects for software development, cloud computing, data analytics, and machine learning




























2019 Bossie Award Winners
For more than a decade, InfoWorld has been celebrating the most interesting and innovative open source projects with our annual Best of Open Source Awards, aka the InfoWorld Bossies. Back when we started these awards, open source projects were typically small and (with noteable exceptions like Linux or BIND) only marginally important to enterprise developers and IT. But they were useful tools, and they were free.
Today, the most important software—for software development, for cloud computing, for analytics, for machine learning, and for pretty much everything else—is open source software. Open source software projects—sometimes backed by multiple, even competing, deep-pocketed technology companies—are solving the biggest problems in enterprise computing, and reinventing enterprise infrastructure and applications.
Welcome to the 2019 InfoWorld Bossie Awards. In this year’s winners, you’ll find not just the best open source software, but the best software, that the world has the offer.
— Doug Dineley

BPF Compiler Collection
The Extended Berkeley Packet Filter (eBPF) is spreading throughout the Linux world, replacing network stalwarts like iptables and making low-cost observability tools running inside kernel space practical and (mostly) secure.
Efficient observability is the goal behind the BPF Compiler Collection, which comprises a suite of compiler tools for creating and running eBPF code within either Python or Lua. The project also includes a large number of example programs that run the tracing and filtering gamut, from probing the distribution of memory allocations in your code to filtering HTTP packets.
The use of eBPF for system observability will likely explode towards the end of the year, when the book by Netflix’s master kernel and performance engineer Brendan Gregg, BPF Performance Tools, arrives in print. Do yourself a favor and start digging in now to be ahead of the curve.
— Ian Pointer

Wasmer
WebAssembly — Wasm for short — promises lightning-fast startup and a tiny footprint, making it superbly suited to serverless architectures and IoT edge devices. Leading the charge in WebAssembly server runtimes is Wasmer, thanks to a blindingly fast, near-native execution speed that simply crushes the competition.
Wasmer combines a stand-alone runtime and a toolkit to compile and target WebAssembly binaries – WebAssembly modules, CLI executable apps, and binary libraries embeddable inside existing code. Similar to what Node.js does for JavaScript, Wasmer allows WebAssembly to be run anywhere.
Based on Cranelift Code Generator, Wasmer provides language integrations that cover Go, C/C++, C#, Python, R, Rust, Ruby, and PHP, with runtimes for Linux, Mac, and Windows (if still somewhat experimentally on Windows due to the Emscripten implementation). Wasmer’s NPM-like package manager, WAPM, rounds out the offering nicely with authenticated, ready-to-run libraries.
The year 2019 has seen Wasmer add two supplemental back-ends to Cranelift (including an LLVM runtime delivering faster execution speed through optimizations), along with support for WASI (WebAssembly System Interface) and SIMD parallelism. WASI is key to application portability across operating systems. SIMD support will bring huge performance gains to math-intensive applications like cryptography and video processing.
— James R. Borck
Language Server Protocol
Some of the most remarkable innovations in software in recent years have been in the toolchains—e.g., the LLVM compiler framework, a library for implementing compilers. The Language Server Protocol from Microsoft fills another tooling niche for software developers: It provides a two-way channel between a compiler or language toolchain and the IDE or editor used to create the code.
Developers need live feedback from their coding tools. Not just static lookups of standard library functions, but interactive details about the code they’re writing. The Language Server Protocol enables this by providing a JSON-RPC standard for communications between development tools and language servers, which provide language documentation and features like auto-complete during editing sessions.
Dozens of languages — from Ada to YANG and most everything in between—have Language Server Protocol implementations.
— Serdar Yegulalp

Serverless Framework
Nothing beats serverless architectures for reducing operational overhead. Unfortunately, that reduced overhead often comes with increased architectural complexity and cloud vendor lock-in. Serverless Framework inserts a vendor-agnostic abstraction between your serverless application and popular cloud implementations like Amazon Web Services, Microsoft Azure, Google Cloud Platform, and Kubernetes.
Serverless Framework not only frees you to choose among different deployment targets, but allows you to test, deploy, and manage event-driven, function-as-a-service applications more quickly and easily. After you create your functions, define your endpoints, and specify a target cloud environment, Serverless Framework wraps it all up — your code, the security and resource artifacts, and cloud deployment YAML — and deploys your project. Plus, the framework’s onboard, automated instrumentation begins monitoring and capturing metrics, providing notifications out-of-the-box.
The developers behind the project were busy this year fortifying Serverless Framework with real-time monitoring, security, and integration testing that reaches deeper into the application management lifecycle. New provisions let you manage credentials and access policies for stronger security, and these can now be tapped programmatically. A new collection of plug-and-play components (still beta) that provide a head start on common use cases, from static websites to full-stack web applications.
In all, Serverless Framework creates a seamless developer experience that removes much of the stress and many of the pitfalls of building serverless applications.
— James R. Borck

Istio
Microservice architectures may simplify development, but as the number of services explodes, managing their communications becomes stupendously complex. Istio, from the Kubernetes universe, lifts the inter-service networking burden from developers’ shoulders by rolling discovery, load balancing, access control, encryption, traffic management, and monitoring into an infrastructure-level solution. There’s no need for developers to work this logic into the services themselves.
Commonly called a “service mesh,” Istio manages all of the space that sits between containers and orchestrated services in a Kubernetes cluster—the network fabric. Istio uses Envoy proxy “sidecars” to mediate all communications between services in the service mesh. Any changes to the network in your cluster can be made via high-level abstractions, rolled out gradually, and rolled back if they prove problematic. Istio also generates statistics about traffic behavior, so you’re not in the dark about service performance.
— Serdar Yegulalp

Envoy
The standard service proxy for Kubernetes, Envoy just seems to go from strength to strength. After graduating as one of the first Cloud Native Computing Foundation projects, preceded only by Prometheus and Kubernetes, Envoy found its way into the heart of service meshes like Istio and AWS App Mesh and is rapidly becoming an integral part of most Kubernetes setups. Huge production deployments, like those at Reddit, prove that Envoy can work at scale.
The past year has also seen the release of Envoy Mobile, which steers many of the benefits of Envoy (such as circuit-breaking, retry-handling, observability, and consistency) into a consistent, cross-platform library for both iOS and Android. While still in an early release stage, Envoy Mobile holds a lot of promise for 2020.
— Ian Pointer

Kong
If you’re building APIs, you don’t want to reinvent the wheels, plural—wheels like rate limiting, load balancing, authentication, logging, and so on. Kong, open sourced by Mashape (later Kong Inc.) in 2015, provides all of that and more. The company also offers Kong Enterprise, an enterprise-grade API platform built on the open source core.
Kong provides most everything needed to complement the API set of an application stack out of the box. In addition to the staples mentioned above, this includes features like circuit breakers, health checks, OAuth, transformations, caching, geo-replication, and much more. If it’s not included by default, you’ll probably find it among the dozens of plug-ins on the Kong Hub.
Kong also plays well with the wealth of cloud-native tools out there. Kubernetes users who want to tightly integrate Kong with their clusters can draw on the Kubernetes Ingress Controller for Kong, again for minimal reinventing of the wheel. Kong Enterprise adds not only support but pro-level automation and visibility tools.
— Serdar Yegulalp
Pulumi
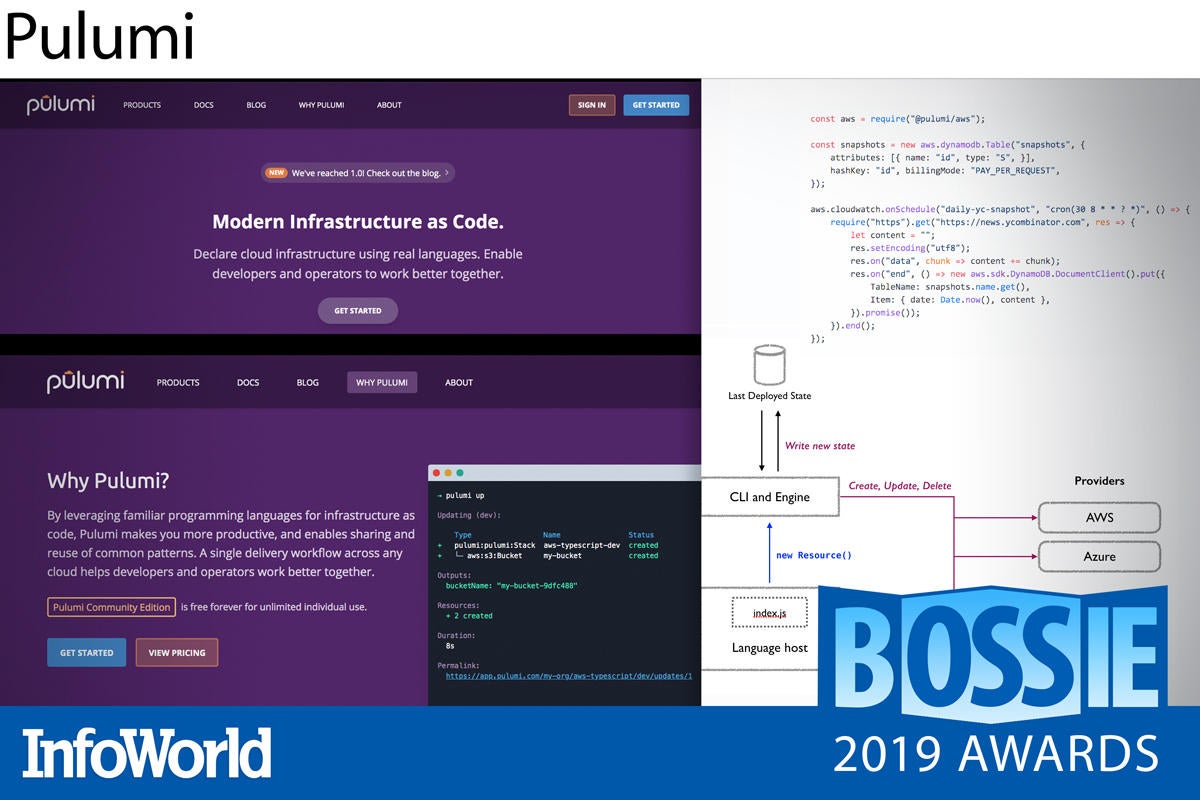
Typically, IT infrastructure is either cobbled together by hand (highly laborious), assembled with scripts that call dozens of APIs (highly complex), or provisioned through a tool like Terraform that executes configuration files (highly specialized). Pulumi offers a different, common-sense, hiding-in-plain-sight answer that steers between these rocks and hard places. Instead of using bewildering new tools or awkward collections of old ones, you declare the infrastructure programmatically using your regular, old, favorite programming language. No YAML required!
Best of all, Pulumi lets you provision and manage infrastructure—in the same way—in all of the major cloud services (Amazon, Azure, Google) as well as any Kubernetes system. Combining a cloud object model, an evaluation runtime, and desired state, Pulumi allows you to provision and manage all kinds of resources—from serverless code snippets and static websites to common applications or app patterns—across clouds.
Pulumi code can be written using JavaScript, TypeScript, Python, and Go, which covers the vast majority of enterprise use cases. The library of examples provides plenty of common patterns that can be used as-is or expanded on.
— Serdar Yegulalp

Sysdig
Cloud-native technologies like Kubernetes and Cloud Foundry are already complex. Add a microservice architecture to the mix, and monitoring becomes a major challenge. Sysdig provides a set of tools that not only provide insight into the performance of container-based applications, but also help reveal anomalies and security threats.
Sysdig Inspect captures container state at the kernel level, allowing you to detect performance issues, track trends, and troubleshoot errors before issues become serious bottlenecks. With Sysdig Falco, you define “normal” behavior for your containers and Falco’s rules-based filtering engine will fire off alerts and even trigger prescriptive actions when abnormal behavior is detected. Sysdig Prometheus combines the ability to instrument nearly any metric with easy querying and real-time visualizations that aggregate the runtime data from your distributed containers, apps, and services.
The past year brought improved alert customizations and triggers, more depth and granularity to the dashboards (with additions such as CPU/memory usage and capacity thresholds), and an enhanced heads-up rules display inside the security policy editor.
Containerized applications introduce unique performance challenges and vulnerabilities. The Sysdig tools help you gain a tighter grip on both container performance and container security.
— James R. Borck
Kraken
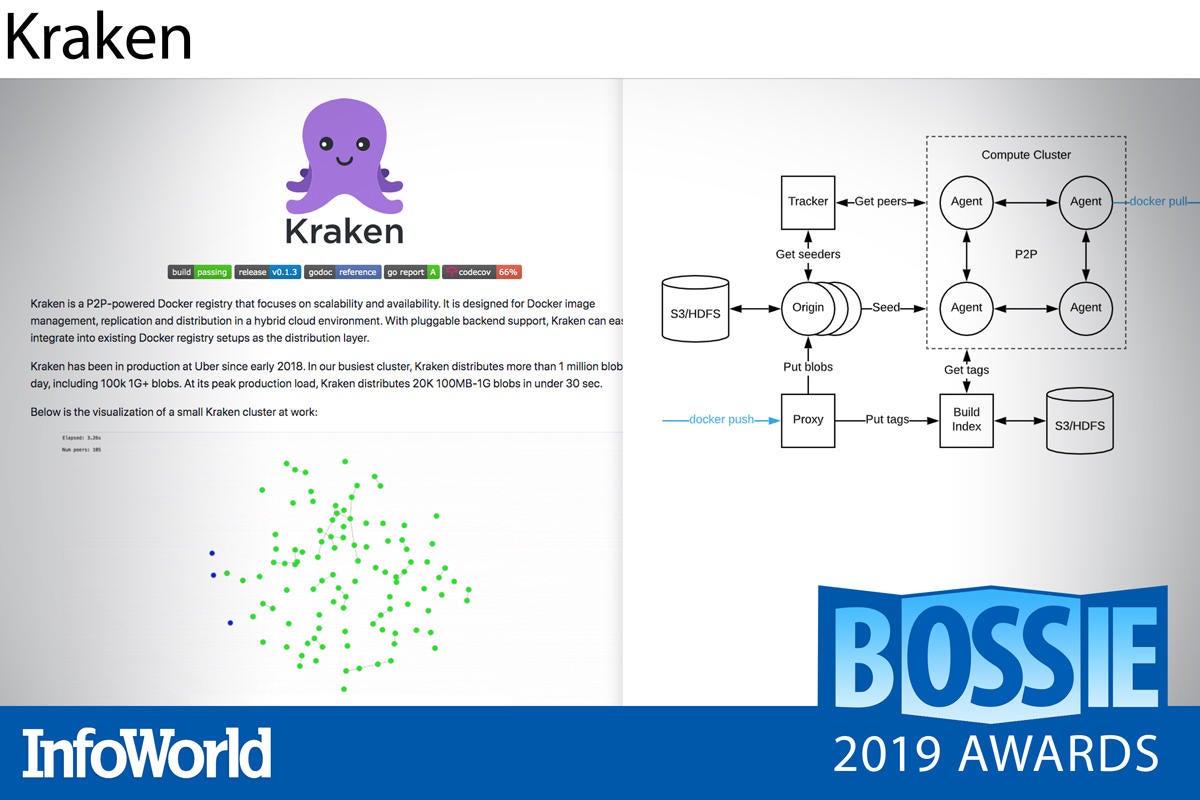
Large-scale container deployments require a high volume of Docker image transfers, which means latency spikes and scaling challenges—especially when you’re pulling those images across multi-zoned data centers. What can you do about it? For Uber Engineering, the answer was to release the Kraken.
Kraken is a highly scalable, peer-to-peer caching and distribution layer for Docker registries that can pull terabytes of image data in seconds. At the heart of Kraken is a self-healing, torrent architecture comprising three primary components. Origin seeder nodes cache image data pulled from pluggable back-end blob storage like Amazon S3 or HDFS. Tracker nodes create an in-memory global view of all available peers and seeders. Peers implement the Docker registry interface and autonomously execute the image pull requests.
Peers work in parallel to assemble tens of thousands of one-gigabyte blobs in seconds to launch jobs in a fraction of the time it would take a traditional, centralized registry. And Kraken offers good optimization and tuning parameters so as not to overload your network. If you’ve already exhausted the usual tricks to mitigate Docker startup latency, you’ll want to give Kraken a try.
— James R. Borck
Anaconda
The Anaconda Distribution is a curated, soup-to-nuts collection of open source Python (and R) packages for machine learning and data science projects. Setting Anaconda apart from other distros is the Anaconda Navigator, a graphical desktop environment for launching applications and managing packages, and Conda, Anaconda’s home-grown package manager.
Because so many packages have version-specific dependencies, keeping multiple installations from colliding—and keeping them all up-to-date—would be onerous if not impossible without Conda. Conda manages all of the dependencies and updates of the Anaconda public repository as well as third-party channels. Pip—Python’s native package manager—is fine for installing and managing Python packages, but Conda handles not only Python packages but dependencies outside the Python ecosystem.
Anaconda delivered some much-needed performance relief to Conda this year. With so many libraries in the installation, updates were becoming gallingly slow to download and install. Fortunately, since the summer release of Conda 4.7, the package manage is feeling much lighter and faster.
Available for Linux, Windows, and MacOS, Anaconda Distribution is a first-rate machine learning and data science ecosystem that supports GPU training and provides a useful job scheduler. and its permissive BSD license makes it attractive to developers.
— James R. Borck

Kotlin
Call it “Java without tears.” Created by JetBrains, the outfit that developed the IntelliJ IDE for Java, and released in a public beta in 2011, the Kotlin language runs on the JVM like Java and interoperates seamlessly with Java libraries. But it also does away with much of Java’s verbosity, adds strong functional programming features, and handles safety problems like null pointer exceptions more elegantly. And Google supports Kotlin as a first-class language for creating Android apps, meaning those who switch to Kotlin aren’t losing one of the biggest markets for Java.
One major theme in Kotlin is taking ideas only partly implemented in Java and making them major parts of the language and toolchain. Kotlin 1.3, released in late 2018, added the ability to compile Kotlin directly to platform-native code, something long unavailable in Java except as a commercial add-on. Another new feature in this vein is contracts, a way for functions to describe how they work to the compiler, which are now used by all functions in the Kotlin standard library. The long-term plan isn’t to clone Java, but to push past Java wherever possible.
— Serdar Yegulalp
Julia
As data science explodes in importance, so does the demand for fast and easy tools for numerical computing. The Julia language was designed from the ground up to deliver the convenience of Python, the speed of C, and the concessions to mathematicians found in Fortran, R, and Matlab. The result is a programming language that strongly appeals to all kinds of math-and-stats users—data scientists, research scientists, and engineers, as well as financial analysts and quants.
Julia 1.0 arrived in 2018 after nine years of development, seven years in public beta. The milestone release consolidated the key features—machine-native speed, math-friendly syntax, multiple dispatch, asynchronous I/O, parallelism, package management—and the general stability of the language. Since then, three major point releases of Julia have brought dozens of new features to improve both its math-and-stats and general programming mojo.
— Serdar Yegulalp
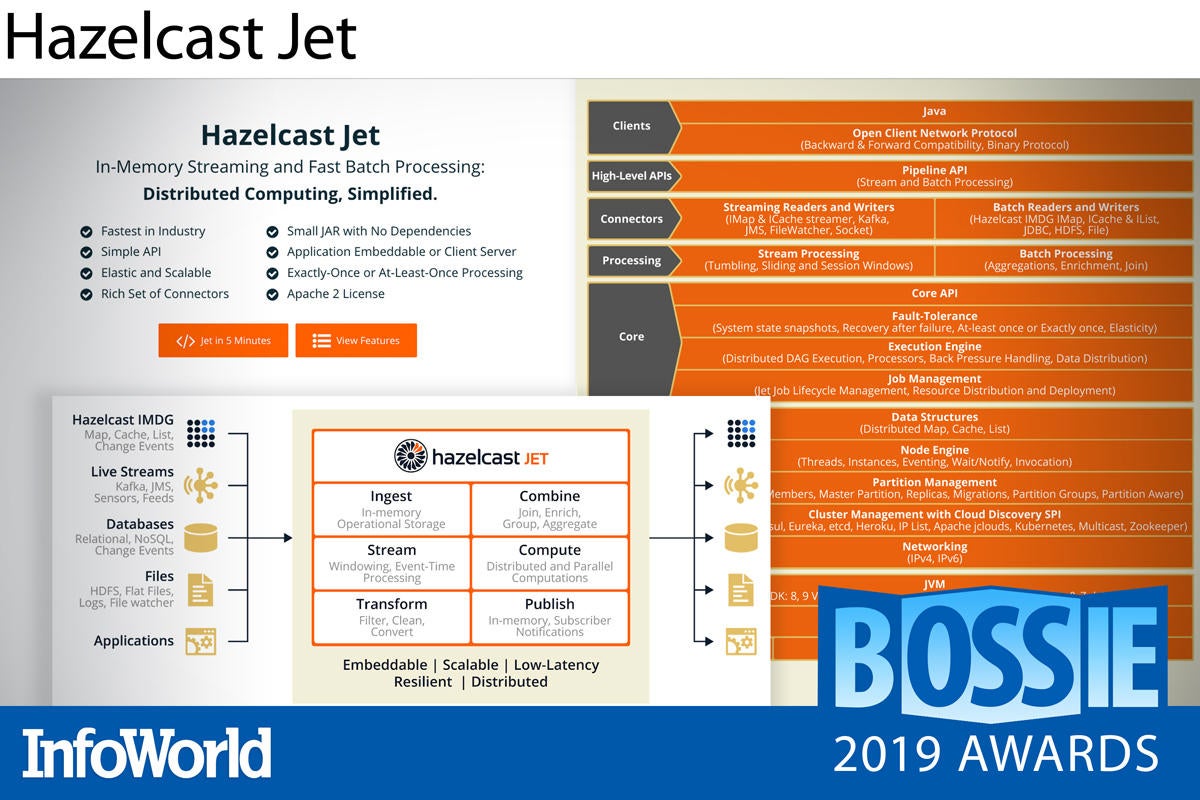
Hazelcast Jet
This year Hazelcast, known for its open source in-memory data grid, delivered the first GA release of Hazelcast Jet, an embeddable, distributed stream processing engine for Java. Although newly GA, Hazelcast Jet 3 has been percolating for years and proven highly reliable. (The 3.x versioning brings Jet in line with Hazelcast’s flagship IMDG product versioning.)
Under the hood, Hazelcast Jet uses the java.util.stream API to create a multi-threaded, data ingest network that operates efficiently in high-frequency scenarios. Plus, connectors let you easily tap data sources like Hazelcast IMDG, HDFS, and Kafka to enrich streams. Jet is a particularly good solution for real-time edge applications like monitoring for IoT sensor networks and fraud detection for payment processing networks.
The GA release of Hazelcast Jet brought full support for Java 11, improved insight into stream diagnostics, new pipeline transforms and aggregation features, and lossless job recovery (in the enterprise edition). Java developers will feel at home using familiar concepts like map, filter, and reduce. If you’re looking to embed distributed real-time intelligence into stream processing Java applications, you should look into Hazelcast Jet.
— James R. Borck
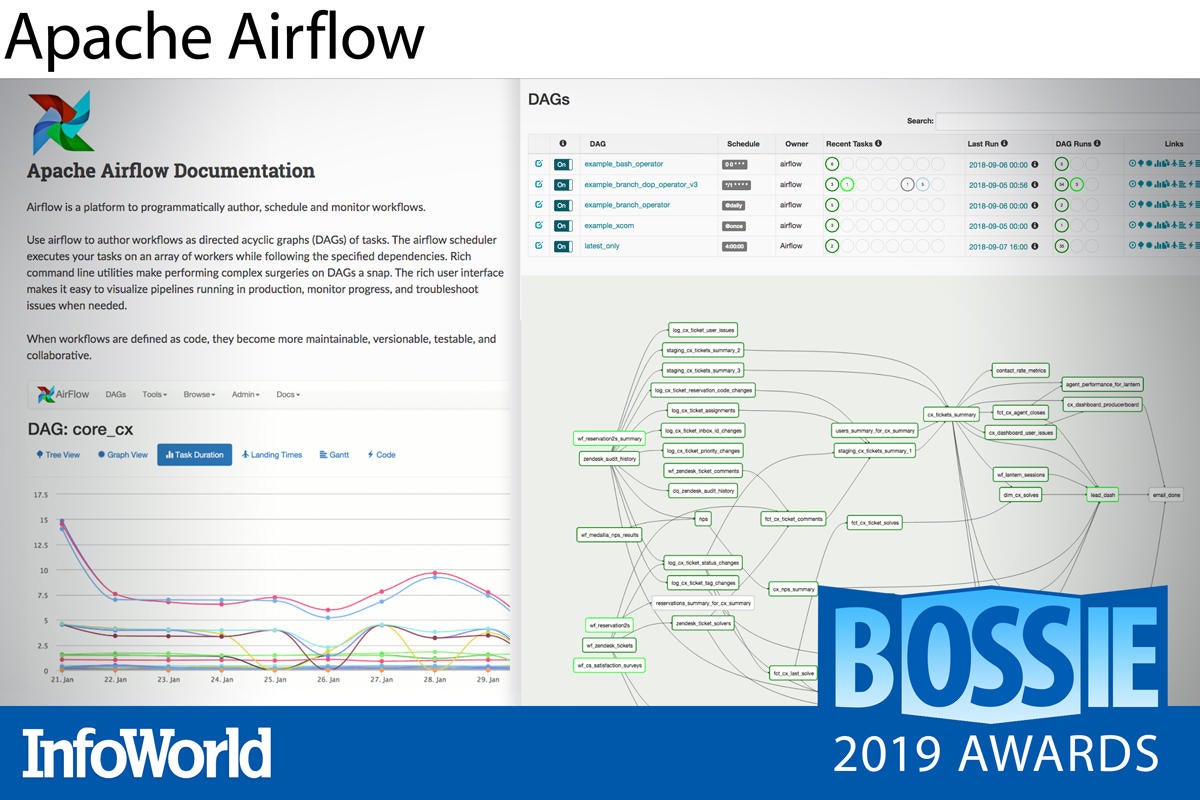
Apache Airflow
Apache Airflow is a Python-based platform to programmatically author, schedule, and monitor workflows. The workflows are directed acyclic graphs (DAGs) of tasks, and you configure the DAGs by writing pipelines in Python code.
Airflow can generate a web server as its user interface. The website can show you your DAGs in a number of views and allows you to operate on the DAGs. In addition, Airflow has a command line interface that allows for many types of operation on a DAG, as well as for starting services and for development and testing.
You can define your own operators and executors and extend the Airflow library so that it fits the level of abstraction that suits your environment. You can parameterize your scripts using the Jinja templating engine. Airflow has a scalable modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is backed by a database, which can be SQLite (for development and test only) or any of the common relational databases.
— Martin Heller

GridGain
GridGain open sourced the Ignite codebase to the Apache Software Foundation some five years ago, and the company has been delivering enterprise-grade features, updates, and enhancements for the in-memory data grid platform ever since. The GridGain Community Edition, which debuted in March of this year, packages Apache Ignite with those same signature GridGain tweaks and patches, serving to optimize performance and reliability, enhance security, and simplify the maintenance of mission-critical deployments.
GridGain Community Edition offers scalable clustering, native replication, and good backup and recovery options, making it well-suited for serving data-intensive applications from distributed data centers—and GridGain supports on-prem, cloud, and hybrid deployments. More advanced aspects of the GridGain feature set are still pay-to-play. But with GridGain Community Edition, a solid platform for high volume, in-memory streaming and real-time event processing is just a free download away.
— James R. Borck
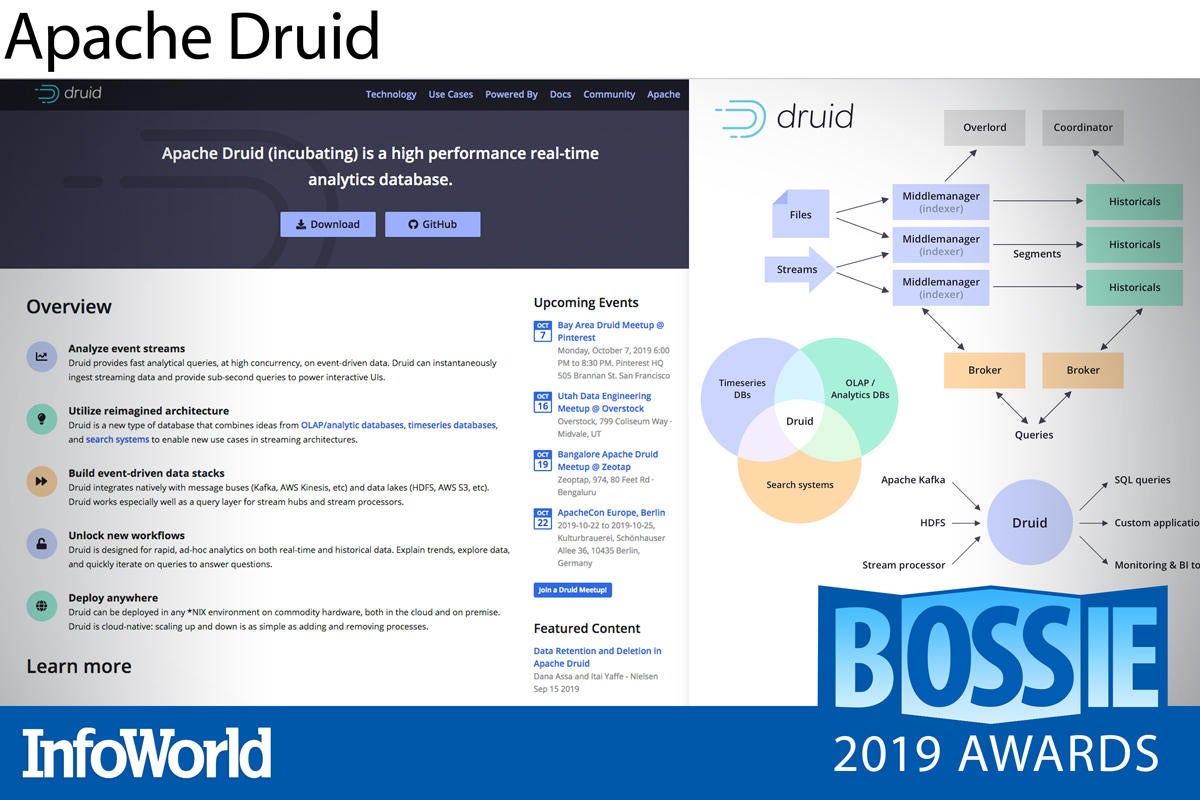
Apache Druid
Apache Druid is a column-oriented time series database and analytics engine that brings real-time visualization and low-latency queries to high-velocity, event-driven data. Druid combines streaming ingest, OLAP-style batch ingestion, and search technology to slice, dice, and transform both real-time and historical data. Superior scalability and lightning-fast ad hoc query responses make Druid a better choice than traditional data warehouses for interactive applications and high-concurrency workloads.
Druid is admittedly something of a behemoth. Clusters comprise multiple servers and processes in order to independently handle ingestion, querying, or workload coordination. But with this complexity comes maximum flexibility and reliability. Although Druid is still in the Apache incubation phase, it is already highly stable, fault tolerant, and production ready—either on premises or in the cloud.
For more advanced Druid tooling, I recommend running the Imply distribution, which adds a drag-and-drop GUI, advanced analytics, and wizard-driven Kafka integration, along with monitoring and management extras. And for more reliable coupling of high-volume event sources with downstream analytics, consider adding Apache Kafka to the mix. Here the Confluent distro makes a solid choice. Kafka and Druid make a great team for real-time, event-driven analytics.
— James R. Borck

TensorFlow
Of all the excellent machine learning and deep learning frameworks available, TensorFlow is the most mature, has the most citations in research papers (even excluding citations from Google employees), and has the best story about use in production. It may not be the easiest framework to learn, but it’s much less intimidating than it was in 2016. TensorFlow underlies many Google services.
TensorFlow 2.0 focuses on simplicity and ease of use, with updates like eager execution, intuitive higher-level APIs (Keras), and flexible model building on any platform. Eager execution means that TensorFlow code runs when it is defined, as opposed to adding nodes and edges to a graph to be run in a session later, which was TensorFlow’s original mode. TensorFlow 2.0 continues to support TensorBoard for graph visualization and diagnostics.
— Martin Heller
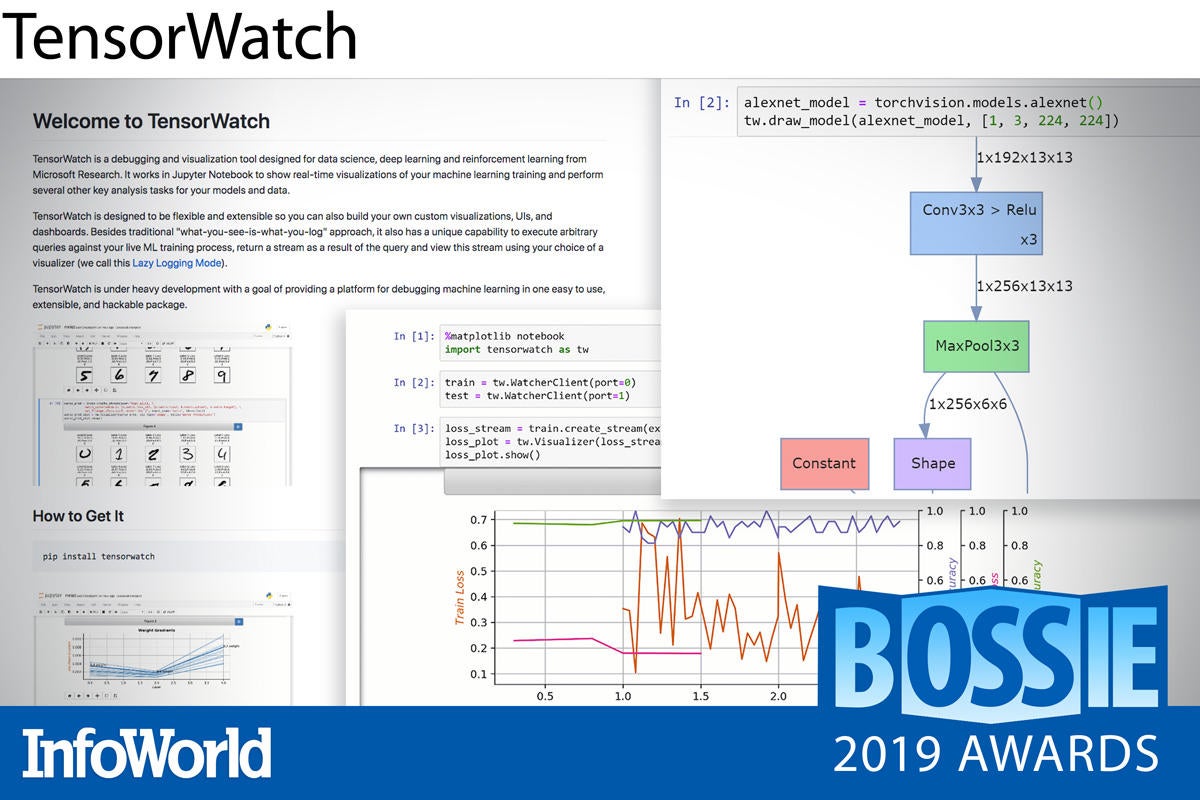
TensorWatch
While TensorBoard makes it easier to understand, debug, and optimize TensorFlow programs, and recently PyTorch programs, it operates on log files after the training is complete and runs in its own user interface. The logging required for TensorBoard has considerable overhead.
TensorWatch is a Python library for debugging and visualization of deep learning models from Microsoft Research that can display graphs in real time as the models train. It also offers useful pre-training and post-training features including model graph visualization, data exploration through dimensionality reduction, model statistics, and several prediction explainers for convolution networks.
TensorWatch provides interactive debugging of real-time training processes using either Jupyter Notebooks or Jupyter Lab. In addition to the direct logging mode used by TensorBoard, TensorWatch supports lazy logging mode, which allows TensorWatch to observe the variables with very low overhead. Then you can perform interactive queries that run in the context of these variables and return streams for visualization.
— Martin Heller

PyTorch
After bursting onto the deep learning scene in 2018 and instantly becoming a popular choice for research, PyTorch became suitable for production in 2019. With the arrival of the PyTorch 1.0 release and the addition of TorchScript, a JIT-compiled subset of Python combined with a fast C++ runtime, the framework is most definitely ready for prime time. If Facebook is running PyTorch at trillion-operations-a-day scale, then it should most certainly satisfy the rest of us.
In addition to production-readiness, the past year has seen the ecosystem around PyTorch mature. There is now a central hub, PyTorch Hub, for storing pre-trained PyTorch models of all shapes and sizes, with associated text, visual, and audio libraries that continue to add cutting-edge techniques, all packaged up and ready to use. It’s no wonder PyTorch has become a favorite of many data scientists, and it looks to continue to make deep learning more accessible into 2020 and beyond.
— Ian Pointer
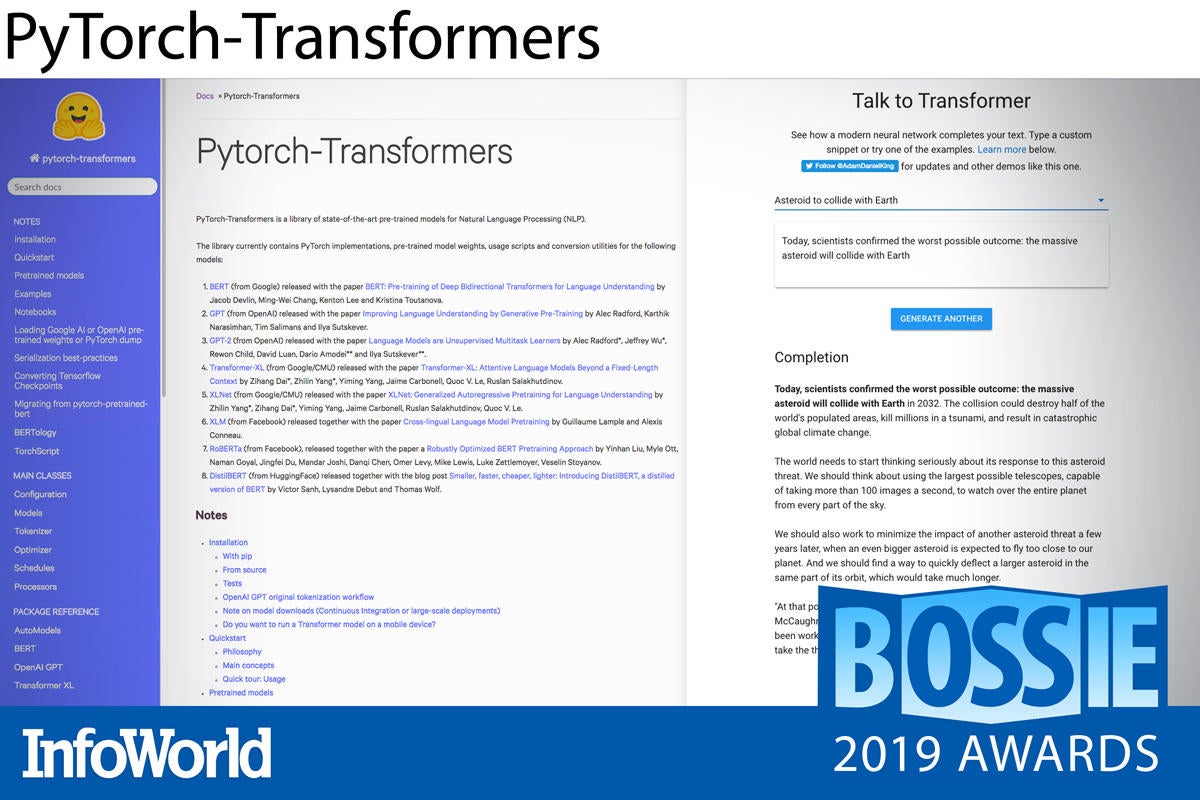
PyTorch-Transformers
The developers at Hugging Face have performed an invaluable service to the PyTorch and NLP (natural language processing) communities with PyTorch-Transformers. The repository contains implementations of the most current, state-of-the-art, NLP research models such as BERT, GPT-2, and XLNet. The implementations are normally updated within a week to include new model or weight releases.
With a unified API for all of the models, as well as thorough documentation for using pre-trained models (with conversion from TensorFlow-trained models also supported) or training your own from scratch, PyTorch-Transformers is a godsend for anyone requiring baselines for their own research. At the same time, the library remains practical enough to use in products like Hugging Face’s own Talk To Transformer.
— Ian Pointer

Ludwig
Ludwig is a Python toolbox from Uber, based on TensorFlow, that mitigates the complexity of neural network programming. Ludwig lets data science novices train and test sophisticated deep learning models without having to write any code; just parameterize a declarative YAML configuration file and off you go. Naturally, experienced data engineers can still tweak the parameters under the hood.
Ludwig lets you define a data source (currently CSV file or Pandas DataFrame) and select your features and encoders. Then Ludwig’s preprocessor goes to work, splitting the data set for training and testing, constructing a neural network, and iterating through different model optimizations. Onboard visualization tools allow you to inspect the test performance and predictive merits of a model. And Ludwig’s programmatic API can be imported directly into Python projects, extending the usefulness of the toolkit beyond a mere command line tool.
Ludwig supports plenty of data types (from text and images to time series) and a number of neural net encoders (including multiple CNN/RNN combinations and ResNet for larger image processing networks). Ludwig plays well with other Uber tools—including Horovod for distributed GPU training—and will soon add support for Amazon S3 and HDFS storage.
If you’re looking for faster iterative experimentation in deep learning, Ludwig offers a very promising shortcut.
— James R. Borck

RAPIDS
Usually, finding a faster way means finding an entirely different way—the old, familiar, deeply entrenched method has to be scrapped before you can speed things up. Not so with RAPIDS, a data science framework that speeds up machine learning without forcing you to ditch what you know and what you already use.
RAPIDS allows machine learning models to be trained directly on GPUs with in-memory processing, speeding up the training process by orders of magnitude even when compared to other GPU training methods. It works by providing functional equivalents to common Python data analysis tools, chiefly Pandas DataFrames. In some cases, all you need to change is the import statements in your scripts.
One significant shortcoming in RAPIDS is limited platform support. The framework currently runs only on Ubuntu and CentOS, and works best with the Anaconda distribution of Python. It currently lacks support for generic Python environments by way of pip installs. But the time RAPIDS saves by harnessing GPUs for data preparation and model training more than makes up for these downsides.
— Serdar Yegulalp
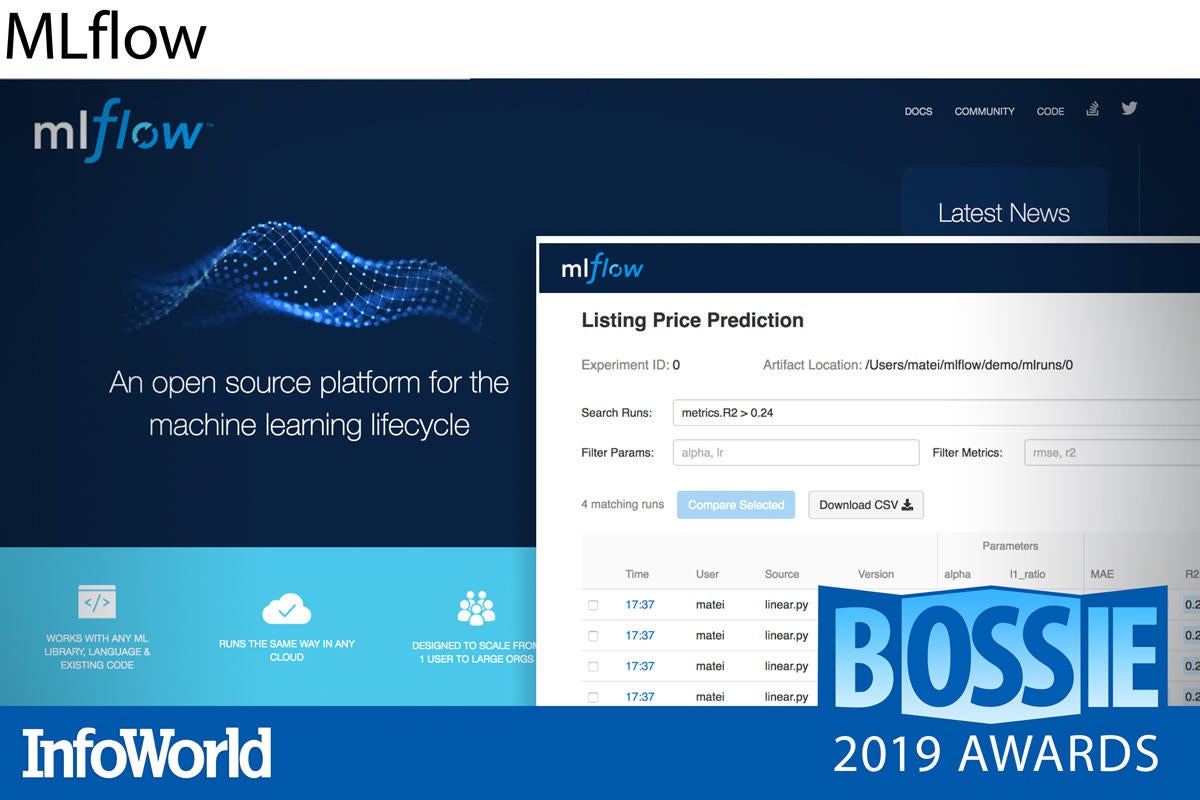
MLflow
Machine learning projects have a life cycle all their own. Experiments are difficult to track, models are difficult to roll out, and results are difficult to reproduce. MLflow was created to make machine learning projects as manageable as other software development projects, with consistent and repeatable ways to prepare data, track code and configurations and output, share models and workflows, and deploy models to production.
MLflow provides tools for each major component and phase of a machine learning project. For machine learning experiments, MLflow provides an API to track and compare results. For reproducing the environment used to generate results, MLflow offers a code-packaging format based on Conda and Docker. And for delivering models to different deployment platforms, MLflow provides a model packaging format that allows predictions to be served from the model, while preserving its relationship to the data and code used to create it.
MLflow is agnostic to both programming language and platform, running on Linux, Windows, and MacOS and working with any machine learning library (TensorFlow, PyTorch, etc.). MLflow is written in Python, so plays best with the Python ecosystem, but it also works closely with R and Java, and has a REST API for working with most any other language.
— Serdar Yegulalp
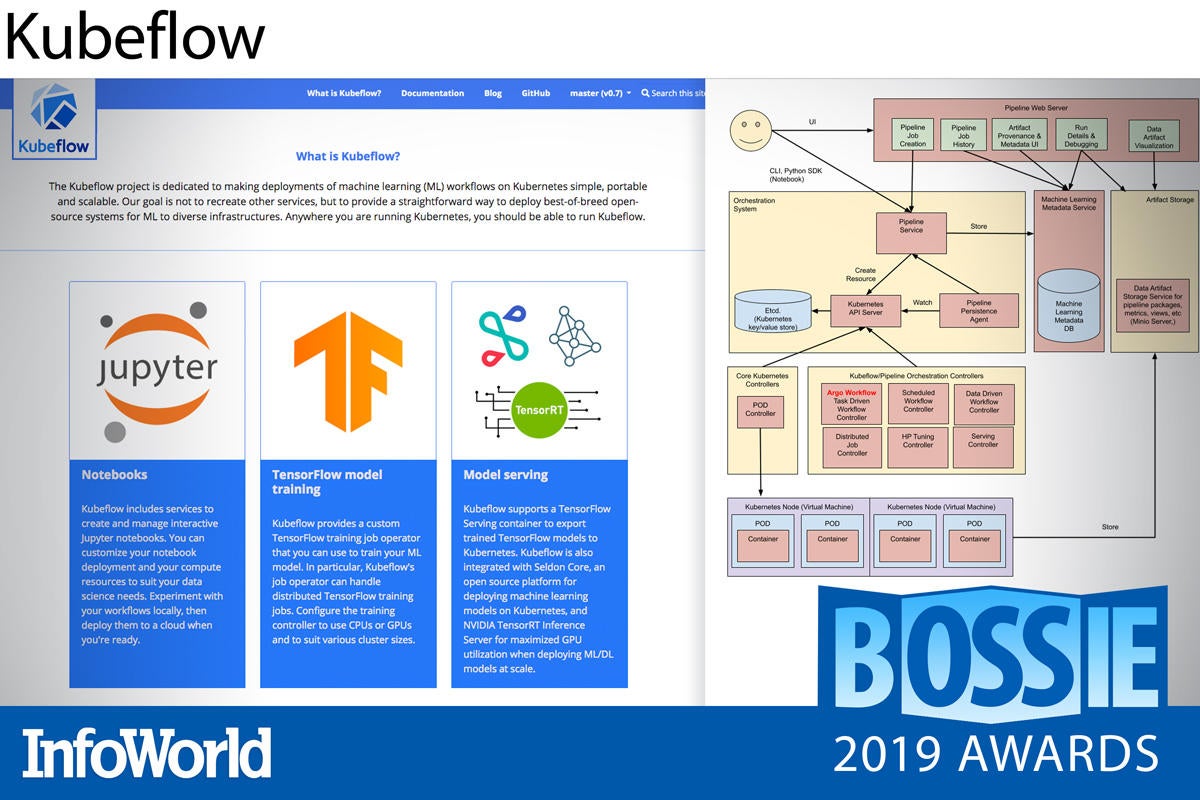
Kubeflow
Kubeflow might sound like it’s cynically merging the two hottest things in IT right now, Kubernetes and machine learning, but it addresses two very real problems that organizations have had to solve from scratch over and over again: How to take machine learning research from development to production, and how to take the telemetry from production back to development to further more research.
Based on the TensorFlow Extended platform from Google, Kubeflow has evolved to become more agnostic, supporting competing machine learning libraries like PyTorch, MXNet, and Chainer, and gaining support and contributions from companies like Chase, Microsoft, and Alibaba. Working to simplify the deployment, management, and scaling of machine learning models, Kubeflow is definitely a project to watch for 2019 and beyond.
— Ian Pointer

Delta Lake
Databricks surprised almost everybody earlier this year by open sourcing Delta Lake, which was—and continues to be—an integral part the company’s commercial offering. Able to perform at a petabyte and even exabyte level, Delta Lake is a storage layer for data lakes that provides ACID translations and easy data versioning that allows “time travel” by simply passing a timestamp through an Apache Spark read function call.
While Delta Lake is still in the early stages of open source development (version 0.2.0, released in June, added cloud support for AWS and Azure), it’s being used in production at Viacom and McGraw Hill, so you can trust your data lake with it right now. Delta Lake will likely to be a sleeper hit across many enterprises in the months to come.
— Ian Pointer
Copyright © 2019 IDG Communications, Inc.

